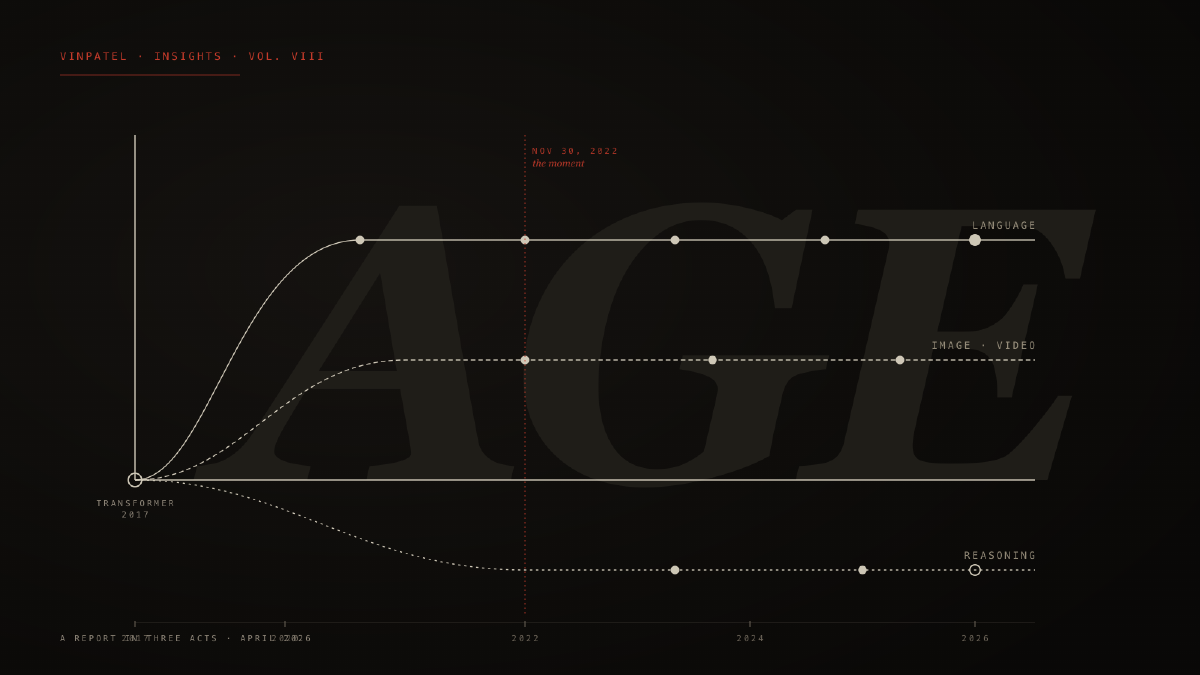

Three years is not a long time in the history of any technology. It is shorter than the gap between the iPhone and the iPad. Shorter than the gap between Netflix mailing DVDs and Netflix streaming. And yet what happened in the three years following November 30, 2022 — the day OpenAI released a research preview called ChatGPT — has compressed into it more conceptual weight than any comparable interval in computing’s seventy-year history. The transformer architecture that quietly underwrote it had been published in 20171. The scaling laws that predicted its trajectory had been written down in 20202. The compute had been accumulating for a decade. But on a Wednesday afternoon, all of it walked through the door at once, in the form of a chat box, and we have not been the same since.
This report is not a celebration of that fact. It is an attempt to take stock. The age we are now in did not begin when the model began to talk. It began when intelligence — once the scarcest resource humans possessed — began to behave like electricity. Always-on, metered, universally addressable, increasingly cheap. Everything downstream of that shift has either already changed, or is about to.
What follows is a three-act report. Act I traces the origin: the architectural and economic preconditions that made the past three years possible, and the inflections that defined them. Act II takes inventory of where we are in April 2026 — what the frontier looks like, what the productivity numbers actually say, and what the labor market has, and has not, done. Act III sketches the decade ahead: not as prediction but as fork. The Age of AI is not one trajectory. It is several, and the variables that determine which one we land in are still inside the room.
Act I · Origin
How It Started
The story of the past three years cannot be told without the seven that preceded them, because the architectural decisions of 2017 are doing most of the work in 2026. In June of that year, eight researchers at Google Brain published a paper titled Attention Is All You Need1. It was a modest claim — that a sequence-to-sequence model could be built without recurrence or convolution, using only the attention mechanism — and an immodest result. The transformer architecture they proposed turned out to be the substrate on which essentially every subsequent model of consequence would be built.
What the transformer did, in retrospect, was unify. It made it possible to train extremely large models on extremely large amounts of data, and — critically — to do so in parallel on accelerators that were getting cheaper and denser every year. For a brief period this was a research curiosity. By 2020 it had become a discipline. In a paper published that January, Jared Kaplan and colleagues at OpenAI demonstrated that the loss of a transformer language model fell as a smooth, predictable power-law function of model size, dataset size, and compute2. They did not say why this was true. They said only that it was, and that the curves did not appear to bend. The implication was startling. If you wanted a more capable model, you did not need a better idea. You needed more of the same idea, applied to more text, on more chips. Two years later, a team at DeepMind would refine these scaling laws — the Chinchilla paper showed that most large models had been undertrained for their size, and that compute should be split more evenly between parameters and tokens3 — but the underlying observation held. The frontier had a rate of advance, and the rate was readable from the equations.
This created a strange industry. The companies that mattered were the ones that could put together the most compute and the most curated text. There were perhaps five of them in the world. Each one trained models in the dark, evaluated them on benchmarks the public did not see, and released them with progressively more cautious framing. GPT-3 (175 billion parameters) had been released in 2020 with an API and a waitlist; it was used mostly by developers, marketers, and the occasional academic4. Most people had never typed a prompt into one. That changed, suddenly and without warning, on November 30, 2022.
A Wednesday in November
ChatGPT was, in technical terms, a thin chat wrapper over a fine-tuned variant of GPT-3.5. It introduced one significant innovation — reinforcement learning from human feedback, RLHF5 — which made the model’s outputs more useful, more polite, and dramatically more willing to follow instructions. But the breakthrough was not in the weights. It was in the interface. For the first time, anyone with a browser could converse with a language model that had read most of the public internet, and have it answer back. Within five days, a million people had signed up. Within sixty days, a hundred million. No consumer product in the history of computing had grown faster6.
What is sometimes forgotten is how quiet the launch was. OpenAI labeled it a research preview. The blog post was four paragraphs long. There was no marketing budget. The product became the cultural event of the decade entirely by word of mouth, in roughly the time it takes to ship a quarterly software release. This is the closest any technology has come to behaving like a contagion.
The Image Detour
Language was not, in 2022, the only axis along which generative models were moving. In April of that year, OpenAI had released DALL·E 2; in July, an independent project called Midjourney opened a closed beta; in August, Stability AI released the weights of Stable Diffusion to anyone who wanted to download them7. Each used a different architectural recipe — DALL·E 2 a diffusion model conditioned on CLIP embeddings, Stable Diffusion a latent-diffusion variant trained on the LAION-5B image corpus — but they shared a property. They could turn sentences into photographs.
The image-generation moment of 2022 was, in cultural terms, almost as significant as the language one. It was the first time most people saw what these models could do, and the first time they encountered the question of what creative labor would mean in their presence. The image axis would later branch into video — Sora in early 2024, Veo and Runway and several Chinese laboratories not far behind — but the conceptual break had already happened by Christmas of 2022. By then, three of the four primary modalities of human communication (text, image, code) were within machine reach. The fourth (audio) would follow within eighteen months.
The Open-Source Pivot
For the first three months after ChatGPT, the conversation was about closed labs. OpenAI, Anthropic, Google, and a handful of well-capitalized challengers held the frontier. Then, in March 2023, Meta released a model called LLaMA — initially under a research-only license — and within a week the weights had leaked onto BitTorrent8. What followed was unlike anything that had happened in machine learning before. Within ninety days, the open-source community had produced quantized variants that ran on consumer GPUs, fine-tunes that approximated GPT-3.5 on certain tasks, and an entire stack of inference servers, evaluation harnesses, and tooling. By the time Meta released LLaMA 2 — properly open-weight — in July, the gravity of the field had shifted. The frontier remained closed, but the floor had dropped: a model good enough to write production code, summarize a meeting, or run a customer service flow could now be downloaded for free.
This had two consequences. The first was economic: the price of a million tokens of intermediate-quality language fell roughly a thousandfold over the next eighteen months9. The second was structural: the field bifurcated. There was now a frontier (Anthropic, OpenAI, Google, and a few late entrants) and there was a long tail (Meta, Mistral, Qwen, DeepSeek, hundreds of smaller projects), and the relationship between them was no longer a hierarchy. By the end of 2024, DeepSeek-V3 had matched the capability of paid frontier models on many benchmarks while being trained for under six million dollars10. The asymmetry of compute that had defined the field since 2020 was no longer absolute.
The Reasoning Turn
The other story of 2024, less appreciated at the time but probably more consequential in the long run, was the reasoning turn. In September of that year, OpenAI released a model called o111. It was unusual. It thought before it answered — generating a long internal chain of intermediate steps, hidden from the user, before producing a final response. On math olympiad problems, on competitive coding, on the kinds of multi-step questions that earlier models had failed badly, o1 was a step change.
What o1 demonstrated was that there was a second scaling axis nobody had been paying enough attention to. The first axis was training compute: bigger model, more data, more pretraining. The second axis was inference compute: how long the model is allowed to think at the moment of answering. By spending more time on a problem, a model of fixed size could produce dramatically better answers. This sounds obvious in retrospect. It was not. For most of the field’s history, inference cost had been treated as something to minimize. After o1, it became a dial.
By April 2026, every frontier lab has a reasoning model — o3, DeepSeek-R1 and its successors, Gemini 3 with adjustable thinking budgets, Claude Opus 4.7. The shift from train-time compute to inference-time compute is one of the main reasons why the productivity-per-dollar of frontier intelligence has continued to climb even as the underlying training runs have begun to plateau.
Act II · State of Play
Where We Are
The frontier in April 2026 is more crowded, less hierarchical, and harder to write about than the frontier of January 2025. There are five frontier-class general-purpose models within a few benchmark points of each other: GPT-5.4, Claude Opus 4.7, Gemini 3.1 Pro, Grok 4, and a Chinese-trained successor to DeepSeek-R112. None of them dominates across every workload. GPT-5.4 leads on multimodal robustness; Claude Opus 4.6 and Grok 4 lead on coding; Gemini 3.1 Pro leads on raw reasoning at 94.3% GPQA Diamond and a context window of one million tokens13. Below the frontier, hundreds of open-weight models — Llama 4, Qwen 3, Mistral Large 2, Phi-4 — handle long-tail workloads at a fraction of the cost. LLM Stats, an industry tracker, logged 255 model releases from major organizations in the first quarter of 2026 alone12.
The honest summary of the frontier is that capability is no longer the moat. It used to be. In 2023 and most of 2024, there was a clear ordering: GPT-4 was better than Claude 2 was better than Llama 2. By 2026 that ordering has dissolved. The differentiation among frontier models is no longer about who is smartest. It is about which model fits which workload, at which price, on which infrastructure, with which guarantees.
The Productivity Paradox
For all the capability, the economy has not yet been transformed. This is the central, awkward fact of 2026. PwC’s 2026 AI Performance Study, surveying executives across 47 economies, found that 88% of respondents reported AI had increased annual revenue in some part of their business, and 87% reported reductions in cost14. These are extraordinary numbers. But the same study found that 74% of AI’s economic value was being captured by just 20% of organizations. A separate, larger MIT-backed survey of US firms found that more than 80% had no measurable productivity or employment impact from AI over the previous three years, despite widespread deployment15. Adoption is everywhere. Transformation is not.
The most candid framing comes from a 2026 WRITER report on enterprise AI16: 79% of organizations face implementation challenges — a double-digit increase from 2025 — and 54% of C-suite executives admit that AI adoption is tearing their company apart. Nearly forty percent of the time saved by AI is then spent on rework, reverification, and reconciliation. Organizations that invest in skills and learning realize value at several times the rate of those that simply deploy.
There is a conventional explanation for this gap, and a less conventional one. The conventional one is that we are still early — that productivity J-curves have always lagged capability J-curves, and that the economy will catch up. The Solow paradox of the 1980s (“you can see the computer age everywhere except in the productivity statistics”) eventually resolved; perhaps this one will too.
The less conventional explanation, and the one I think more accurate, is that the bottleneck is not technological. It is organizational. Most enterprises are not yet structured to absorb a workforce in which a junior analyst, a senior strategist, and a thinking partner can be the same software entity at different prices. The reorganization required to actually capture AI’s value — flatter teams, fewer handoffs, different reporting structures, different metrics — has barely begun in most large companies. Software companies adapted faster because they were already structured around iteration. Banks, hospitals, insurers, governments, and manufacturers were not. They will adapt. The lag is the cost of that adaptation, not evidence that the technology is overhyped.
The composition of who captures the gain matters as much as the absolute size of it. PwC’s 2026 study found that 74% of AI’s economic value globally was being captured by just 20% of organizations14. This is not the conventional Pareto distribution one sees in stable industries; it is the distribution one sees in the early phase of a new general-purpose technology, when the firms with the operational discipline to absorb it pull dramatically ahead of those without. The gap will narrow as the rest catch up. It will not narrow soon.
The Labor Market That Didn’t Break
Predictions in 2023 — including some from people whose models triggered them — suggested that white-collar work would begin to compress within twenty-four months. It has not, or at least not yet. Yale’s Budget Lab, tracking labor market data since the ChatGPT release, finds no statistically significant disruption in the broad employment mix three and a half years on17. The categories most exposed to AI on paper — office and administrative support, computer and mathematical occupations, certain creative roles — have not collapsed. Some are still growing.
This is not because companies have not tried to substitute AI for labor. They have, and visibly. Headlines through 2025 and 2026 have been thick with announcements of layoffs attributed to AI. Layoff trackers count over 30,000 such job cuts in the first quarter of 2026 alone, on top of 55,000 in 202518. But when economists separate out the actual cause from the announced cause, only about 4.5% of layoffs in the period are demonstrably AI-driven. The remainder are attributable to budget pressure, post-2024 revenue softness, or routine workforce correction. AI has become the most palatable cover story for cuts that would have happened anyway. This will be hard to read in 2030, when actual displacement begins. We will have to distinguish between performances of disruption and the real thing.
What has shifted, undeniably, is the composition of demand. An analysis of nearly all US job postings from 2019 through March 2025 found that postings for routine, automation-prone roles fell 13% after ChatGPT’s debut, while demand for analytical, technical, and creative roles grew 20%19. Anthropic’s 2026 Labor Market Report, which mines real-world Claude usage data, shows a similar pattern: AI is being used most heavily for augmentation tasks (research, drafting, analysis) rather than full automation of any single job20. The mid-decade story is one of recomposition, not replacement.
The vulnerable populations are not yet the populations that have lost work. Workers aged 18–24 are 129% more likely than those over 65 to worry that AI will obsolete their jobs19. Entry-level positions — the rungs by which knowledge workers traditionally climbed — are quietly compressing. The senior expert is fine for now. The junior is being compressed. This may turn out to be the more important structural fact.
"AI has become the most palatable cover story for cuts that would have happened anyway. We will have to distinguish, at some point soon, between performances of disruption and the real thing."
The Energy Wall
Underneath all of this — under the benchmarks, the productivity studies, the labor market data — there is a substrate fact. AI is now the gravity well of the global computing infrastructure. The constraint is no longer ideas, no longer chips, no longer software. The constraint is electricity.
Modern AI facilities draw 100 to 750 megawatts per site21. A single NVIDIA GB200 NVL72 rack draws 120 to 140 kilowatts. Vera Rubin, the next NVIDIA generation, will take rack-level power density to 250 kilowatts. Between 2020 and 2025, AI server power density increased eleven-fold, and is expected to grow another four-fold by 202721. The IEA projects that AI datacenters alone will consume 90 terawatt-hours globally by the end of 2026 — roughly equivalent to ten gigawatts of always-on capacity, more than the entire power consumption of Switzerland22. Global datacenter critical IT power demand is projected to surge from 49 GW in 2023 to 96 GW by 2026, of which roughly 40 GW will be AI-attributable.
This has reshaped the geography of capital. Power costs vary 4× across US regions ($0.04 to $0.16 per kilowatt-hour); a hyperscaler choosing a site is choosing a multi-billion-dollar bet on grid availability. Microsoft, Amazon, and Google have all signed nuclear power purchase agreements in the past eighteen months, including the reactivation of decommissioned plants23. Texas, Virginia, Wyoming, Iceland, and Saudi Arabia have become — for compute reasons — strategic locations the way petroleum capitals were in the twentieth century. Whether the grid can hold is genuinely uncertain. NVIDIA-backed pilots in late 2025 demonstrated that AI datacenters can flex power consumption in near-real time to match grid availability, which is the kind of thing one only investigates when worried about brownouts24.
The Open Frontier
One last property of the present moment deserves naming. The frontier is no longer a Western frontier. DeepSeek, Qwen, Kimi, Yi, and a handful of other Chinese-trained models now match the closed-frontier on a wide range of benchmarks at one to two orders of magnitude lower cost25. This is partly because Chinese labs have been forced into compute efficiency by export controls on high-end NVIDIA chips, and partly because state and academic resources have been concentrated on the problem in ways American labs cannot match. The resulting models are often released open-weight, which means they enter the global software supply chain with no friction. As of April 2026, somewhere between 30% and 40% of the open-source model downloads on HuggingFace are of Chinese-origin models25. Whatever one thinks about this geopolitically, the technical fact is that the assumption — operative as recently as 2024 — that the frontier was a four-lab race in California is no longer accurate.
Act III · The Next Decade
What Will Be Demanded
The first and most important thing to say about the next decade is that no one knows what will happen, and the people who say they know are not always the ones who do. The forecast spread — from credible sources, all of whom are paying attention — is so wide that it itself is the most important piece of information.
That said, there are several structural transformations that do not require AGI to occur. They require only the continuation of the present trajectory at roughly its present rate. These are the changes I would plan around.
Intelligence as Infrastructure
The most important shift, which I believe will be considered the defining shift of the era when we look back from 2040, is that intelligence is becoming infrastructure. The question is no longer can a model do this task. The question is what is the marginal cost of a unit of cognition, and at what rate is it falling. The answer to the first half is near zero, and falling. The answer to the second is about 4× per year on a constant-quality basis9. If that rate holds for five more years, the cost of solving a hard reasoning problem will fall by a factor of a thousand. Whatever the qualitative cap of model capability turns out to be, the economic cap of deploying it is dropping out from under us.
This is what I mean by the electricity analogy. Electricity did not transform the world because it produced something humans could not do (light, motion, communication). It transformed the world because it made those things effectively free at the margin. The factories rebuilt themselves around the assumption of abundant power. The home rebuilt itself around the assumption of abundant power. Cities rebuilt themselves. The transformation happened over four decades, and the productivity gains lagged the deployment by twenty years, and then arrived in a wave that did not stop. We are now somewhere between 1900 and 1920 on that curve, with intelligence in the role of electricity. The assumption of abundant cognition has not yet been built into the economy, and once it is, the economy will not look the same.
The Atomization of Software
The most immediate consequence is the dissolution of software-as-we-know-it. The SaaS architecture — discrete applications, subscription pricing, browser tabs as the primary interface — was an artifact of 2010 economics. It assumed that integrating two systems was hard, that switching costs were high, that having a separate tool for each job was rational. None of those assumptions survives a world in which an agentic interface can compose any tool with any other tool at runtime, on demand, for the price of a few pennies of inference.
The agentic systems market grew from $8.6 billion in 2025 to a projected $263 billion by 203526. That number is implausibly precise but directionally right: when intelligence is infrastructure, the overlay that uses it eats the application below it. The question for software companies is no longer what feature should we build next. It is what would still be true about our business if every customer had an agent that could rebuild it from scratch in a weekend. The companies whose answer is our data, our distribution, our network, our trust will survive. The companies whose answer is our UI will not.
Knowledge Work, Restructured
The story of knowledge work in the next decade is not replacement. It is recomposition. A senior strategist is not replaced by AI; the strategist now does the work of three. A junior analyst is not replaced; they are expected to produce at the level of a former senior, and the rung beneath them — the apprentice work — has dissolved. This will create training-pipeline crises in every knowledge profession by 2030. The mechanisms by which a human got from 0 to 30 years of expertise relied on doing the boring work that AI now does better. We have not yet figured out what replaces apprenticeship. This is one of the most important under-discussed problems of the decade.
The corollary is that the expert generalist — a person who can move between domains, hold a topic loosely, and direct intelligence rather than produce it — becomes a scarcer and more valuable archetype. The deep specialist remains valuable for the highest-stakes work but is now in competition with a model that has read every paper in the field. The generalist has the leverage. This is the inverse of the trend of the past forty years. It deserves more attention than it gets.
Education’s Tutor for Every Mind
In 1984 the educational psychologist Benjamin Bloom published a paper showing that students who received one-on-one tutoring outperformed students in a normal classroom by two standard deviations27. He called this the 2-sigma problem: how do you replicate the conditions of one-on-one tutoring at scale, since tutoring everyone is economically impossible? The answer Bloom never imagined is that, by 2026, it isn’t. The cost of a personalized tutor for every student in the world is now bounded by inference compute. The question is whether educational institutions will route around the technology, integrate it, or be replaced by it.
The early evidence is that integration works. Studies of Khanmigo, Duolingo Max, and several university pilots show meaningful gains in mastery for students using AI tutors as supplements28. The harder question is structural: when a motivated 14-year-old in Lagos has access to the same quality of tutor as a motivated 14-year-old in San Francisco, and the only difference is whether the institutions around them are organized to support the use, the inequality story shifts. The bottleneck will become institutions, not technology. This is not how educational disruption is usually framed. I think it will turn out to be how it actually proceeds.
Science’s Compounding Decade
In 2020, DeepMind released AlphaFold 2, which solved a problem — the prediction of protein structure from sequence — that had stymied biology for half a century29. The pattern of that release matters more than the result. A computational system, trained on existing data, produced an output that compressed decades of human research into a usable database. The Protein Data Bank, which had grown by tens of thousands of structures over forty years of laboratory work, gained hundreds of millions of predicted structures within months.
The pattern is repeating. AlphaProof and AlphaGeometry have collapsed competition mathematics. AlphaChip is designing semiconductor floor-plans at superhuman rates. New models are appearing at six-month intervals across materials science, drug discovery, climate modeling, and high-energy physics. The mechanism in each case is the same: train on the existing literature and experimental output, then use the model as a search engine over the much larger space of plausible answers. The decade ahead is going to be, I think, the most scientifically productive decade since the post-war period — not because AI will do science, but because it will collapse the time between hypothesis and experiment by a factor of ten or more.
The Creative Question
I will be brief here because I am uncertain. When abundance becomes free, what does taste cost? When any image can be conjured, the bottleneck of creativity moves from execution to discrimination. This is good for creators with strong points of view and bad for creators whose value was technical proficiency. It is good for institutions that curate well and bad for those that simply produce. It is good for human attention as the scarce resource and bad for any business model that assumed scarcity of supply. I do not think the creative industries collapse. I think they reorganize around a smaller number of distinctive voices — voices that AI can imitate but not originate — supported by a much wider tail of routine production that AI handles. This will feel, for a few years, like a desert. Then a renaissance. Then a steady state we cannot yet imagine.
The Three Risks That Matter
I want to be specific about which risks I think deserve the most attention, because the public conversation tends to flatten them.
Concentration of power. Frontier AI development requires capital, talent, and energy at a scale that very few entities can muster. The number of organizations capable of training a frontier model in 2026 is somewhere between five and ten. By 2030 it may be three to five. This is the most serious near-term risk: not that AI does anything in particular, but that the small number of actors who control it will make decisions affecting billions, with very limited democratic accountability. The EU AI Act, the US executive orders, and a patchwork of national policies are early attempts to bound this; whether they are sufficient is unknown.
Misuse. The same capabilities that make AI productive make it useful for fraud, disinformation, surveillance, and (in the limit) bioterrorism. The democratization of capability — an upside almost everywhere else — is a downside here. The defensive technologies (provenance signing, watermarking, detection systems) are running about eighteen months behind the offensive ones. We will live with this gap.
Alignment. The most discussed risk in the AI safety community, and the hardest to write about responsibly. The short version is that as models become more capable agents — as they take real-world actions on behalf of users — the difficulty of ensuring they pursue what we actually want, as opposed to what we technically asked for, scales. The major labs invest meaningfully in this. Whether it scales fast enough is contested. I am not in a position to adjudicate. I am in a position to say that anyone confident either way should be discounted accordingly.
The Decade Fork
Combining these threads, I see three plausible decade-end states. They are not predictions. They are forks.
In the concentrated state, three to five frontier labs end the decade controlling the bulk of the world’s high-capability inference, with the rest of the economy renting access on terms set by those few. In the democratized state, open-weight models continue closing the gap with the closed frontier, value migrates to layers above the model (data, distribution, trust, taste), and the diffusion of capability resembles the diffusion of the web in the 2000s. In the contested state, geopolitical bifurcation produces two roughly symmetric stacks — one Western, one Chinese — with the rest of the world choosing between them or building stripped-down sovereign alternatives.
I do not know which of these we will land in. I think the variables that determine the answer are still mostly inside the room — they are policy choices, technical choices, and compounding small decisions made by millions of practitioners about what tools they build with and what licenses they ship under. Anyone telling you the outcome is fixed is wrong. Anyone telling you the trajectory is not bending sharply somewhere is also wrong.
The Ancient Frame
I want to close on a note that is less data and more disposition. I have spent twenty-five years building software, and the past three of those years working closely with these models. I have also spent a good portion of my life with the texts of the Indian philosophical tradition — texts that, two and a half millennia before the transformer paper, were already asking the question this technology forces us to confront. What is the relationship between the mind that knows and the world it knows? The Upanishads, the Yoga Sutras, the Bhagavad Gita — these are not technical documents, but they are documents about the structure of cognition. They describe, in their own idiom, exactly what these models are doing: a pattern that emerges from pattern, a knowing that is not located in any one place, a discrimination between signal and noise that is the ground of all skilled action.
I do not think the technology of the next decade will be best navigated by people who are comfortable with software. I think it will be best navigated by people who are comfortable with the question of what cognition is for. The first group — the engineers — built what we now have. The second group — and this includes humanists, philosophers, religious thinkers, artists, and the unusual technologists who hold both — will determine what we do with it. Every era of technology has had this fork. None has had it with stakes this high.
The Age of AI is not, in the end, a story about machines. It is a story about what humans choose to do when intelligence is no longer the rate-limiting resource. The five-thousand-year-old answer is the same as the answer that will matter in 2036: be thoughtful about what you direct intelligence toward. Be honest about what you do not know. Build with care for the second-order effects. The substrate has changed. The discipline has not.
Three years is not a long time. We have been given more capability in three years than any generation before us was given in a century. The work now is to be worthy of it.
- Vaswani, A. et al. *Attention Is All You Need.* NeurIPS 2017. arxiv.org/abs/1706.03762
- Kaplan, J. et al. *Scaling Laws for Neural Language Models.* OpenAI, January 2020. arxiv.org/abs/2001.08361
- Hoffmann, J. et al. *Training Compute-Optimal Large Language Models* (Chinchilla). DeepMind, March 2022. arxiv.org/abs/2203.15556
- Brown, T. et al. *Language Models Are Few-Shot Learners* (GPT-3). OpenAI, May 2020. arxiv.org/abs/2005.14165
- Christiano, P. et al. *Deep Reinforcement Learning from Human Preferences.* NeurIPS 2017. The technique was operationalized for instruction-tuned models by Ouyang et al., 2022 (InstructGPT).
- Hu, K. *ChatGPT sets record for fastest-growing user base.* Reuters, February 1, 2023.
- Rombach, R. et al. *High-Resolution Image Synthesis with Latent Diffusion Models* (Stable Diffusion). CVPR 2022. arxiv.org/abs/2112.10752
- Touvron, H. et al. *LLaMA: Open and Efficient Foundation Language Models.* Meta AI, February 2023; weights leaked in March 2023.
- Cottier, B. et al. *Pricing of frontier model APIs has fallen approximately 4× per year on a constant-quality basis.* Epoch AI cost-tracking, 2024–2026.
- DeepSeek-AI. *DeepSeek-V3 Technical Report.* December 2024. Disclosed training cost: $5.6M for the final run.
- OpenAI. *Learning to Reason with LLMs* (o1 system card). September 2024.
- LLM Stats. *Q1 2026 model release tracker.* llm-stats.com — 255 model releases logged from major organizations in Q1 2026.
- LM Council. *AI Model Benchmarks April 2026.* lmcouncil.ai/benchmarks
- PwC. *2026 AI Performance Study.* PwC Global, 2026. pwc.com/gx
- MIT NANDA Initiative. *State of AI in Business 2026.* As reported in Fortune (April 2026).
- WRITER. *Enterprise AI adoption in 2026.* writer.com
- The Budget Lab at Yale. *Evaluating the Impact of AI on the Labor Market: Current State of Affairs.* budgetlab.yale.edu, 2026.
- MetaIntro. *AI Layoffs Cover Story 2026.* Layoff-attribution analysis, 2026.
- Cazzaniga, M. et al. *Job postings analysis.* Reported in Harvard Business Review, March 2026: *Research: How AI Is Changing the Labor Market.*
- Anthropic. *2026 AI Labor Market Report.* Based on anonymized Claude usage data.
- SemiAnalysis. *AI Datacenter Energy Dilemma — Race for AI Datacenter Space.* semianalysis.com, 2026.
- International Energy Agency. *Electricity 2024.* Projection: 90 TWh AI-attributable datacenter consumption by 2026.
- Microsoft, Amazon, Constellation Energy. *Three Mile Island Unit 1 reactivation power purchase agreement.* September 2024.
- Tom's Hardware. *NVIDIA-backed trial shows AI data centers can flexibly adjust power use in near real time.* 2025.
- HuggingFace download statistics, Q1 2026; complemented by Stanford HAI *AI Index Report 2026.*
- Forecasted by industry analysts; cited in Top 10 Technology Predictions for the Next Decade, 36Kr, 2026.
- Bloom, B. *The 2 Sigma Problem: The Search for Methods of Group Instruction as Effective as One-to-One Tutoring.* Educational Researcher, 1984.
- Khan Academy, Duolingo, Carnegie Mellon. *AI tutor pilot studies, 2024–2026.*
- Jumper, J. et al. *Highly accurate protein structure prediction with AlphaFold.* Nature 2021.