Local Models Are Finally Good Enough to Ship With
Running local LLMs has crossed a quality threshold that matters for builders—here's why this changes your architecture decisions today.
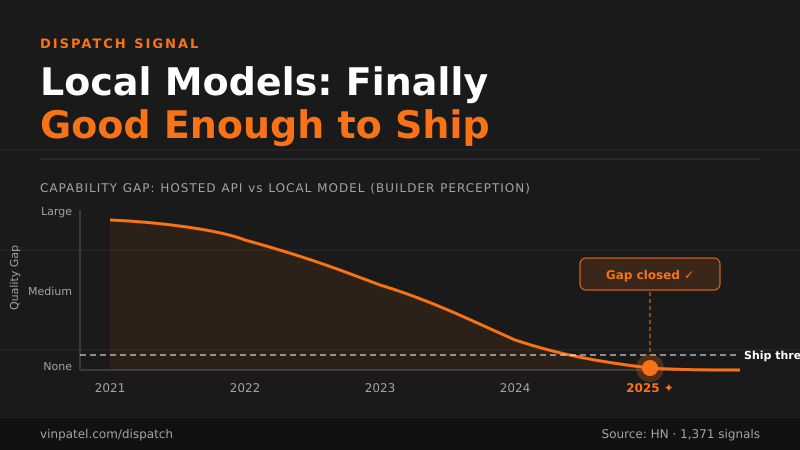
The signal: Local model quality has hit a threshold where HN builders are loudly declaring it’s actually good now—1,371 upvotes worth of loud.
Why it matters: If you’re building products that touch sensitive data, have latency requirements, or need to cut inference costs, the ‘wait until local is ready’ excuse just expired. The gap between hosted API quality and local model quality is no longer a dealbreaker for most production use cases.
The pattern I’m watching: Two signals colliding: the Netherlands just funded a sovereign national LLM, and local models are going mainstream. Privacy-first AI infrastructure is becoming a real architectural category, not just a compliance checkbox. Builders who wire in local model support now will have a serious differentiator when enterprise buyers start asking hard questions about data residency.
What I’d do with this: Spin up Ollama this week and run your current prompt suite against a local model—benchmark it honestly against your GPT-4o calls. If it passes 80% of your eval cases, you now have a cost and privacy lever you can pull without a rewrite.