Claude 4 Benchmarks Signal a New Era for Agentic Coding
Claude 4 pushes SWE-bench past 70% — agentic coding crosses the reliability threshold for solo builders.
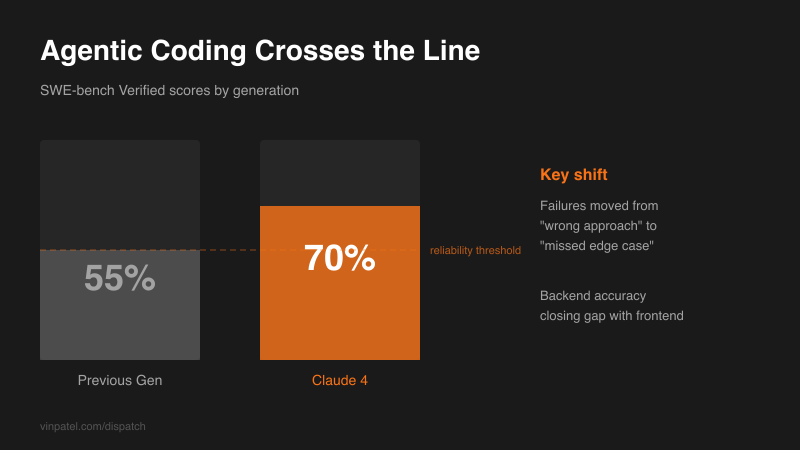
The signal: Claude 4 pushes SWE-bench Verified past 70% — up from 55% in the previous generation.
Why it matters: The jump from 55% to 70% isn’t linear. It’s the gap between “useful assistant needing constant supervision” and “reliable collaborator handling defined scope autonomously.” Failure modes shifted from “wrong approach” to “missed edge case” — a fundamentally different debugging problem.
The pattern I’m watching: Backend accuracy is finally catching up to frontend. Previous models scored 90%+ on frontend but 35-40% on backend. Full-stack agentic workflows are becoming viable for the first time.
What I’d do with this: Start with a contained project — a CRUD API, a CLI tool — and let the agent handle implementation while you focus on architecture and review. The reliability threshold is real, and we’re crossing it.