AMD Lemonade Shows Hardware Wars Moving Local
AMD's Lemonade server combines GPU+NPU for local LLMs — chip makers are serious about on-device inference.
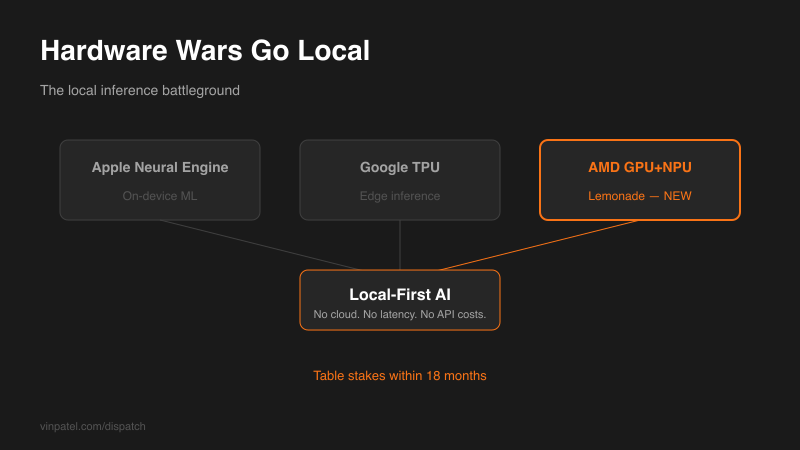
The signal: AMD released Lemonade, an open source local LLM server combining GPU and NPU processing for faster on-device inference.
Why it matters: This isn’t another local LLM wrapper — it’s AMD throwing real engineering weight behind hybrid processing. The GPU+NPU combination moves past “just throw more VRAM at it.” Local deployment without requiring gaming rigs is becoming real.
The pattern I’m watching: Apple’s Neural Engine, Google’s TPU, now AMD’s NPU play — the next battleground is efficient on-device processing. NVIDIA dominated cloud training, but local inference is wide open.
What I’d do with this: Test local deployment now — not just for privacy, but for cost and latency. Design your AI features assuming local inference will be table stakes within 18 months. Users are getting tired of sending everything to the cloud.